
TL&DR: The discussion on whether “LISP scales better than EVPN” became irrelevant when the bus between the switch CPU and the adjacent ASIC became the bottleneck. Modern switches can process more prefixes than they can install in the ASIC forwarding tables (or we wouldn’t be using prefix-independent convergence).
Now, let’s focus on the dynamics of campus mobility. There’s almost no endpoint mobility if a campus network uses wired infrastructure. If a campus is primarily wireless, we have two options:
- The wireless access points use tunnels to a wireless controller (or an aggregation switch), and all the end-user traffic enters the network through that point. The rest of the campus network does not observe any endpoint mobility.
- The wireless access points send user traffic straight into the campus network, and the endpoints (end user IP/MAC addresses) move as the users roam across access points.
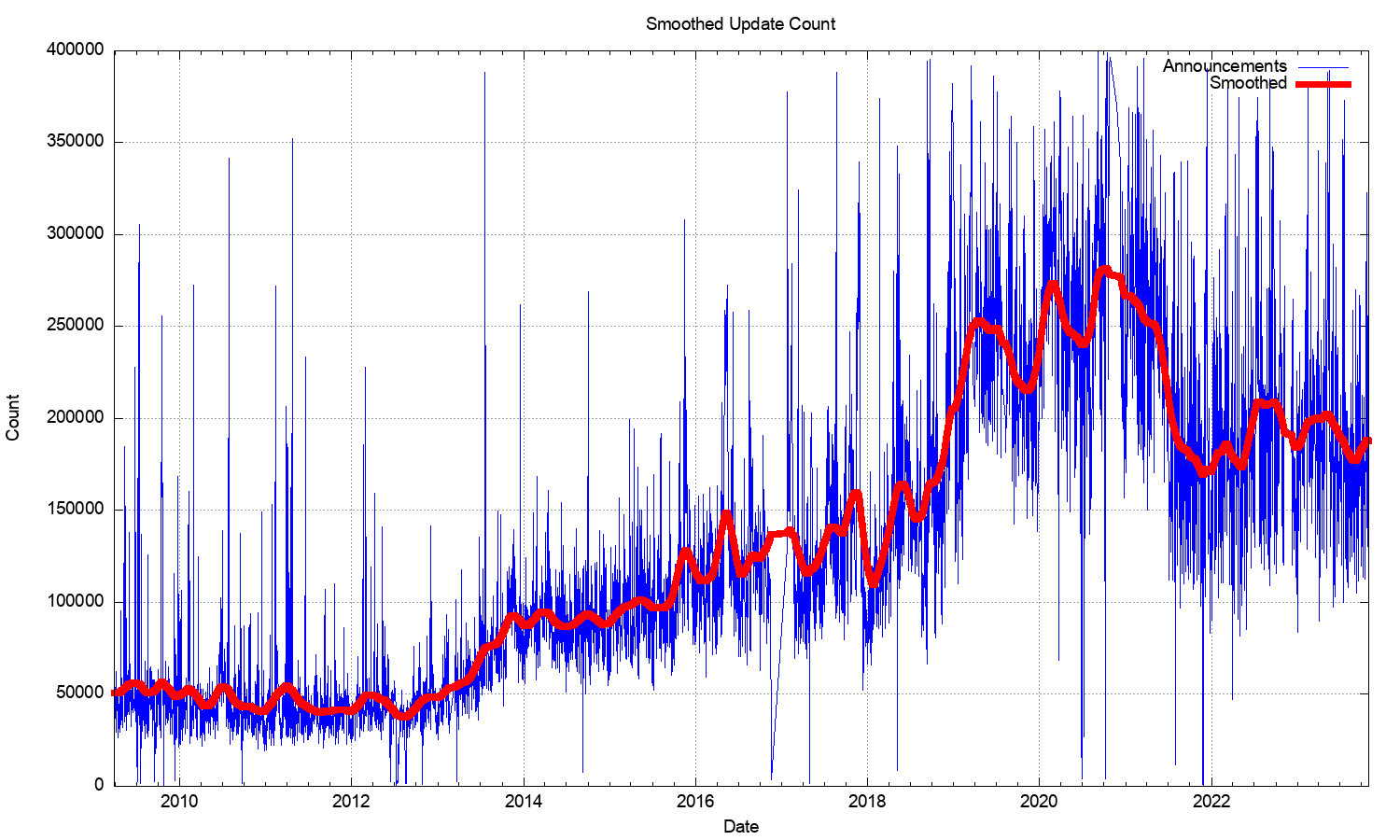
Therefore, the argument seems to be that LISP is better than EVPN at handling a high churn rate. Let’s see how much churn BGP (the protocol used by EVPN) can handle using data from a large-scale experiment called The Internet. According to Geoff Huston’s statistics (relevant graph), we’ve experienced up to 400.000 daily updates in 2021, with the smoothed long-term average being above 250.000. That’s around four updates per second on average. I have no corresponding graph from an extensive campus network (but I would love to see one), but as we usually don’t see users running around the campus, the roaming rate might not be much higher.
However, there seems to be another problem: latency spikes following a roaming event.
I have no idea how someone could attribute latency spikes equivalent to ping times between Boston and Chicago to a MAC move event. Unless there’s some magic going on behind the scenes:
- The end-user NIC disappears from point A, and the switch is unaware of that (not likely with WiFi).
- The rest of the network remains clueless; traffic to the NIC MAC address is still sent to the original switch and dropped.
- The EVPN MAC move procedure starts when the end-user NIC reappears at point B.
- Once the network figures out the MAC address has moved, the traffic gets forwarded to the new attachment point.
Where’s latency in that? The only way to introduce latency in that process is to have traffic buffered at some point, but that’s not a problem you can solve with EVPN or LISP. All you can get with EVPN or LISP is the notification that the MAC address is now reachable via another egress switch.
OK, maybe the engineer writing about latency misspoke and meant the traffic is disrupted for 20 msec. In other words, the MAC move event takes 20 msec. Could LISP be better than EVPN in handling that? Of course, but it all comes down to the quality of implementation. In both cases:
- A switch control plane has to notice its hardware discovered a new MAC address (forty years after the STP was invented, we’re still doing dynamic MAC learning at the fabric edge).
- The new MAC address is announced to some central entity (route reflector), which propagates the update to all other edge devices.
- The edge devices install the new MAC-to-next-hop mapping into the forwarding tables.
Barring implementation differences, there’s no fundamental reason why one control-plane protocol would do the above process better than another one.
But wait, there’s another gotcha: at least in some implementations, the control plane takes “forever” to notice a new MAC address. However, that’s a hardware-related quirk, and no control-plane protocol will fix that one. No wonder some people talk about dynamic MAC learning with EVPN.
Aside: If you care about fast MAC mobility, you might be better off doing dynamic MAC learning across the fabric. You don’t need EVPN or LISP to do that; VXLAN fabric with ingress replication or SPB will work just fine.

Before doing a summary, let me throw in a few more numbers:
- We don’t know how fast modern switches can update their ASIC tables (thank you, ASIC vendors), but the rumors talk about 1000+ entries per second.
- The behavior of open-source routing daemons and even commercial BGP stacks is well-documented . Unfortunately, he didn’t publish the raw data, but looking at his graphs, it seems that good open-source daemons have no problems processing 10K prefixes in a second or two.
It seems like we’re at a point where (assuming optimal implementations) the BGP update processing rate on a decent CPU exceeds the FIB installation rate.

Back to LISP versus EVPN. It should be evident by now that:
- A campus network is probably not more dynamic than the global Internet;
- BGP handles the churn in the global Internet just fine, and there’s no technological reason why it couldn’t do the same in an EVPN-based campus.
- BGP implementations can handle at least as many updates as can be installed in the hardware FIB.
- Regardless of the actual numbers, decent control-plane implementations and modern ASICs are fast enough to deal with highly dynamic environments.
- Implementing control-plane-based MAC mobility with a minimum traffic loss interval is a complex undertaking that depends on more than just a control-plane protocol.
There might be a reason only a single business unit of a single vendor uses LISP in their fabric solution (hint: regardless of what the whitepapers say, it has little to do with technology).











{kind=link}